

Introduction
In the SEO industry, it’s widely accepted that Google deploys machine learning to improve the quality of search engine results. Machine learning (ML), a branch of artificial intelligence, can be trained to spot patterns like a human expert would. As a result, ML can tell the difference between compelling content and spammy content, making it harder for spammers or cheap marketing tricks to succeed at SEO.
For example, Google has introduced RankBrain, the result of their heavy investment in ML. RankBrain aims to rank content according to the user intent behind the keywords searched on. RankBrain has probably helped reduce the headcount of the Google Search Quality Team, as the algorithm is reliable enough to rank content reliably at scale.
But what about the practitioners of SEO? Most experts rely on their commercial experience in combination with tools and data. While that may be effective, it isn’t scalable to an enterprise level, where it’s common for a team to be working on a site with thousands if not hundreds of thousands of pages.
Machine Learning gives SEO experts and corporations the opportunity to make the SEO process more effective, training computers to help generate solutions at scale. While machine learning and even deep learning are unlikely to replace the SEO expert, it could certainly help them to:
- Avoid mistakes and verify their judgement
- Quantify the ranking benefits of an SEO solution
- Secure implementation buy-in from web development colleagues
- Build business cases for management
Solving an SEO Issue
Any process of improvement needs to begin with in-depth analysis. Just as a doctor would ask you to describe your symptoms before hoping to diagnose a condition, search engine optimisation can only come after a detailed site audit.
The objective of technical SEO is to optimise the site architecture and content to make it more searchable. This usually involves maximising the PageRank (or domain authority) of the desired site pages and tagging up content to make it more meaningful to search engines. Typically, SEOs use their favourite audit tools such as Deep Crawl, Screaming Frog, Google Analytics and others. However, while site audit tools are very helpful in listing most of a site’s architectural issues such as duplicate content, the consultant is still relied upon to investigate why those issues occur.
For example, are issues the result of:
- non www vs www
- url parameter
- malformed menu links
- thin content
- other?
Investigating these potential causes obviously requires a great investment of time. First, the SEO would need to classify each reason for the duplicate content occurring. Once the reasons have been classified, it would then make sense to quantify the extent of SEO error types.
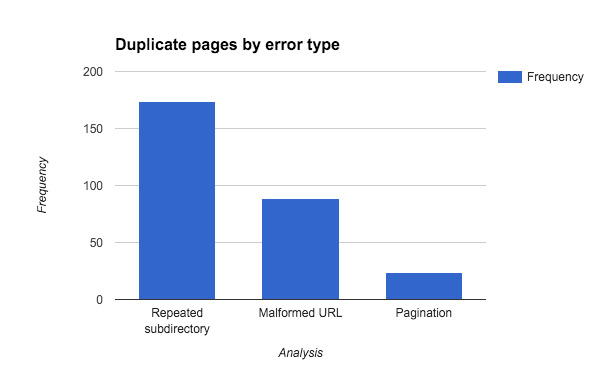
The graph above shows the number of pages for each duplicate content cause on a retail website we worked on last year. Most of the errors in the above example are the result of the client repeating content under a different folder.
Once the audit results have been analysed, an SEO use their knowledge of the appropriate technologies (like HTML, Javascript, or Linux Apache) to present a number of sensible solutions to improve the site content’s potential to rank in Google.
Most competent SEO consultants will use Google Analytics data to help them verify the effects of their solutions. Going further, the data driven SEO will use statistics (beyond the average) to prove a ‘treatment effect’ – that is, that the solution is highly likely to improve rankings in Google. If possible, statistics will also be used to quantify the potential ranking uplift.
The use of statistics is highly effective. But imagine having to do this manual analysis on an ecommerce site with thousands of error pages?
Machine learning changes website auditing
Machine learning is a branch of AI – algorithms learn from data, only limited by the amount and quality of the data you can give them. So they can find patterns and trends without being explicitly programmed for them. Google uses machine learning to grow increasingly more sophisticated and make smart decisions. SEOs should be doing the same.
Let’s suppose that one of the main reasons for duplicate content are pages with thin content. Most SEOs are likely to compare their clients problematic pages with those of the leading competition:
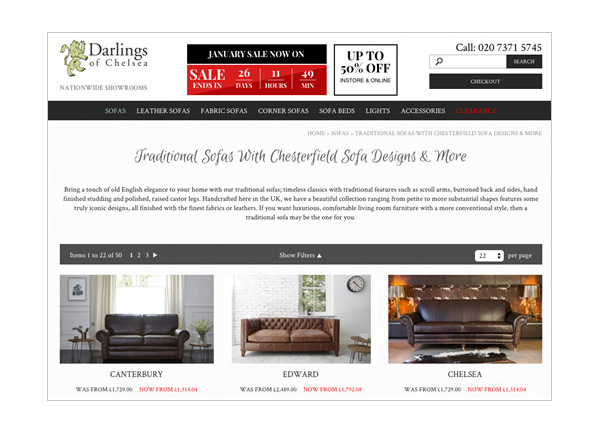
They may use their experience to spot patterns. The above category web page for a luxury furniture retailer shows how an SEO could play a game of ‘spot the difference’ to see what the client website is missing.
If they are mathematically inclined, an SEO could use statistics generated by content strategy audit tools to get an overview of how the problematic pages differ from the normal pages:
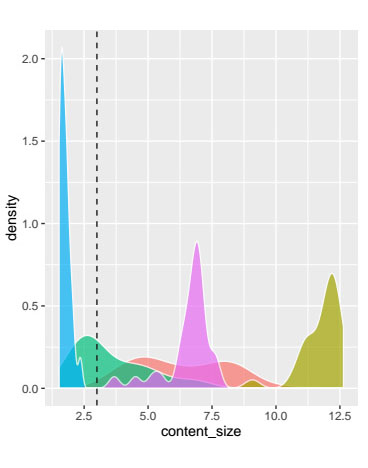
For example, the graph above compares the client site against the leading competitors in terms of content size.
However, machine learning could take things further by automating this kind of analysis and identifying potential predictors for thin content – at scale.
Here’s what our technology platform found for an ecommerce website:
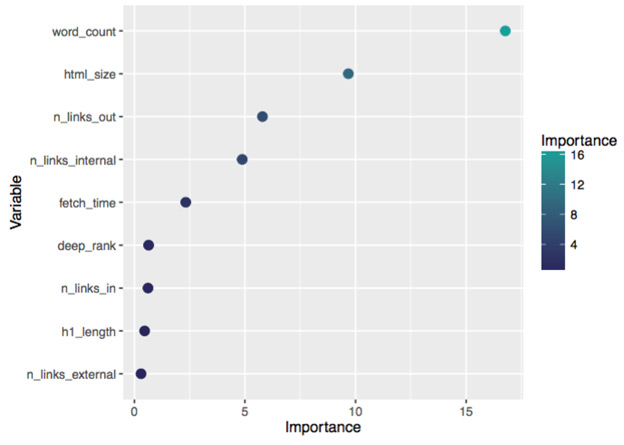
In the example above, our algorithm identified content size (measured in Kilobytes per page) as the most significant reason as to why the pages were thin. Of course, the most actionable metric of them all is the word count, which happens to be the most important predictor.
Bearing in mind that machines can’t really “see” like a human being to compare web pages, the algorithm was still able to take the data and spot the difference using statistics which are visualised below:
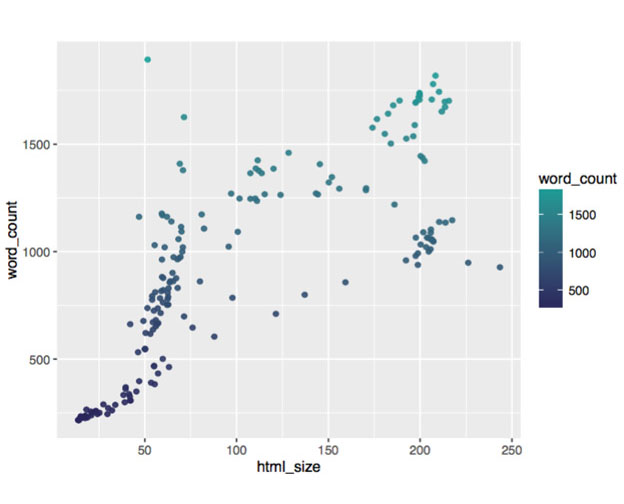
We used a supervised classification based model to predict the whether a page would be thin or fine. The model can be a very powerful and flexible general purpose model, which can be used for classifying and predicting the SEO content error type.
Predicting the type of a page is a classification problem. Supverised classification models like Support Vector Machines (SVMs) have become very popular recently, particularly in the competitive machine learning communities such as Kaggle.
The algorithm looks at the data and selects the content feature that best predicts the page that will have the SEO error or not. Then, it splits the data into two sections, depending on their value of that content feature. Each data split can then be split further by looking at other variables.
We run hundreds of trials to create the machine learning model training the data on 80% of the observations and then tried to predict whether the remaining 20% were okay or thin. The model made predictions on data it had never seen, so the performance of the model would be indicative of it’s performance on future data.
When predicting, the model provides a probability for each observation. When we examine the probability assigned to each observation in the test set (along with the actual value), we can see that our model is very accurate:
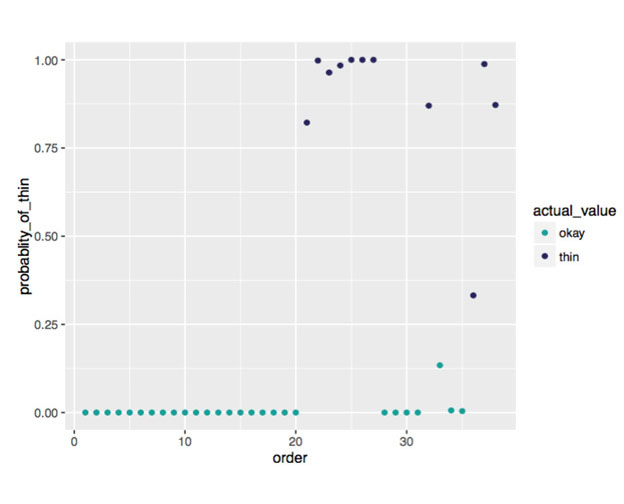
The above graph shows how good our model is at predicting which pages will be identified as ‘thin’ by the Deep Crawl site crawling tool. If we classify every observation with a greater than 0.5 chance of being thin as thin, we can classify the test set almost perfectly. In most cases, machine learning models will not be 100% accurate.
Conclusion
In our example, we could make informed decisions about the changes that would make the biggest difference because of machine learning.
In summary, machine learning gives you the power to:
- Generate accurate SEO recommendations at scale based on patterns
- Provide precise industry specific benchmarks as to how many words should be used (rather than rely on best practice advice that is not usually agreed upon!)
- Get buy-in from web developers, content strategists, UX and other specialists, winning their respect through evidence that’s statistically validated
- Build business cases to secure more budget and improve the website’s searchability. This could be anything from a content marketing campaign to investment in a content strategy
It’s not about replacing SEOs – just making their decisions evidence-based, more informed, and more reliable. Our time and talent should be focused on devising solutions, not manually performing the tasks that machines could do in less time with little effort.
In turn, clients and companies can be more efficient, potentially saving money on consultancy fees or improving the effectiveness of an in-house corporate SEO.
The SEO consultant isn’t going anywhere – but the future SEO consultant uses machine learning to work more effectively. The future is now.